Using Java API to access Google Search Console Data
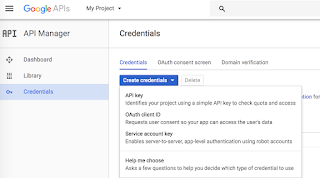
This blog talk about ingesting the Google Search Console data using the Java API. There are various kinds of reports that are available in Google Search Console (GSC). Ex: Search Analytics, Sitemaps, Sites, URL crawl errors/metrics etc. The API endpoints are defined in : https://developers.google.com/apis-explorer/?hl=en_US#p/webmasters/v3/ Before you begin setting up your Java env, make sure you have access to the Google Search Console dashboard and also has an admin access to create the service key for API access. Steps to create service account for API access : 1. Go to API Manager : https://console.developers.google.com/apis/credentials 2. Select your project from the dropdown list. 3. Click on " Create Credentials " and then select " Service Account Key " 4. Provide a service account name and select " P12 " as the key type. 5. Note the email id for this service account and Save the p12 file once you have created the new...
